No mundo dos testes automatizados, os testes são classificados por níveis de validação. Testes que validam uma pequena unidade de código são chamados de testes unitários (unit tests). Quando validam a integração entre componentes, são chamados de testes de integração (integration tests).
Esses dois tipos de testes são os mais comuns. No entanto, também existem testes que simulam a interação real do usuário com a aplicação, conhecidos como testes end-to-end.
Cada tipo de teste gera custos de desenvolvimento, manutenção e execução ao longo da vida de um sistema. Em linhas gerais, quanto mais simples e pequeno um teste, mais barato é escrevê-lo e mantê-lo. Por exemplo, testes unitários são mais baratos que testes de integração.
O tempo de execução dos testes varia e isso também influencia no custo dele. Testes unitários são rápidos, enquanto testes funcionais ou end-to-end demoram mais devido à etapa de preparação que costuma ser bem longa.
Testes bem escritos custam mais para serem desenvolvidos, mas reduzem os custos de manutenção. O oposto também é verdade: testes mal escritos podem até ser mais baratos para serem escritos, mas custam caro para serem mantidos.
Os testes unitários são fáceis de escrever e manter se o código estiver bem desacoplado, pois testam apenas uma pequena unidade de código. Testes de integração, embora mais caros, garantem que a comunicação entre partes do sistema funcione corretamente sem que o tempo de execução aumente.
Com os testes funcionais ou testes end-to-end avaliam a capacidade do software de resolver problemas reais. Como o nome diz eles testam se o software “funciona”. Embora desejáveis, são difíceis de escrever corretamente e são os mais caros de desenvolver, manter e executar.
Entendendo a relação entre o custo e os benefícios que cada tipo de teste trás, como distribuir o “orçamento” que você tem para escrever testes?
Minha estratégia
Minha estratégia favorita é escrever muitos testes unitários, alcançando alta cobertura.
Exemplo: 235 passed in 100s; 99.98% coverage
Também escrevo testes de integração para cenários ideais (happy path) e de falhas esperadas.
Exemplo:
Teste acessar perfil público do usuário @publico
Teste falha ao acessar perfil privado do usuário @privado
Teste falha ao acessar qualquer perfil sem autenticação
Não faria um teste de integração para “Falha ao acessar um usuário com nome inválido” porque um teste unitário já deveria garantir isso. Se a regra mudar, não preciso alterar testes em vários lugares.
Para os testes funcionais ou end-to-end, foco nos fluxos fundamentais do sistema.
Exemplo:
Fluxo de Cadastro (sign up): se esse fluxo quebrar, novos clientes não serão convertidos.
Fluxo de Registro (sign in): se esse fluxo quebrar, clientes não conseguirão usar o produto.
Fluxo de Compra (check out): se esse fluxo quebrar, em um e-commerce, não venderíamos.
Ou seja, escrevo testes funcionais ou end-to-end apenas para garantir que, se algo falhar, a aplicação não se torne completamente inútil.
Estou tentando entender um código bem intrincado e importante do trabalho… é um código bem crítico que resolve um problema bem difícil (merge de objetos) e foi desenvolvido “sob demanda”, ou seja, fizeram uma versão básica e foram incrementando ele com cenários diversos que foram sendo descobertos com o tempo.
Todo mundo na empresa tem medo de mexer com esse código porque, apesar dele ter até uma certa cobertura de testes, não sabemos se esses testes realmente cobrem todos os cenários reais.
Mas preciso entender esse código para fazer uma otimização (ele executa um UPDATE muito demorado no nosso banco de dados e eu preciso remover esse UPDATE).
Eu não sei onde esse UPDATE acontece porque o código é todo elaborado com execuções tardias (lazy) das operações. Então preciso ler tudo para entender onde essa operação está sendo agendada para execução.
Como tenho TDAH é muito difícil, para mim, somente ler o código para entendê-lo. Quando o código é curto e simples tudo bem, mas não é esse o caso. O que eu geralmente faço é um processo de refatoração do estilo do código. Não só em termos de formatação (porque tem ferramentas para isso que já rodam no nosso sistema de integração contínua), mas também em estilo estrutural.
Vou separando cada bloco de refatoração ou função refatorada em um commit em um branch criado especificamente para esse trabalho.
Uma vez que terminei tudo e entendi o funcionamento do código crio um PR (em modo draft) com uma descrição detalhada do que fiz, da separação em commits, necessidade de revisar, como revisar, etc. para meus colegas de trabalho avaliarem e até mesmo responder algumas das minhas dúvidas. Mas o mais importante: inicio a descrição do PR explicando que a aceitação dele é totalmente opcional e até mesmo não indicada por conta dos riscos envolvidos.
Para todo esse processo é imprescindível o uso de uma ferramenta de refatoração automática que possibilite renomear identificadores, extrair funções/métodos, inversão de lógica em ifs, etc. Senão o seu trabalho será miserável.
Munido de todos os requisitos passo a alterar o código da seguinte maneira…
Nomes melhores
Entender um código onde os identificadores são chamados obj, data, tmp, etc. é complicado. Ter identificadores com nomes como “foo_json” que tem um dict() e não uma JSON-string também não ajuda muito.
Renomeie variáveis, funções, métodos, classes, etc. para terem sempre o nome correto. Se estiver difícil escolher um nome para o identificador é porque o código tem outro tipo de problema ou ainda falta compreensão sobre ele.
Early Return
Uso early return pattern para reduzir o volume de indentação do código e o embaraçamento dele (tangled). O objetivo é linearizar os fluxos e criar blocos segmentados com lógica de processamento. Sou um “Never Nester Developer”. 😀
Como já comentei nesse artigo aqui, de modo bem simplificado, o código abaixo:
def f(c1, ..., cN):
if c1 and... cN:
... faz um monte de coisas ...
return 1
return 0
Vira algo do tipo:
def f(c1, ..., cN):
# cenário excepcional 1
if not c1:
return 0
...
# cenário excepcional N
if not cN:
return 0
... faz um monte de coisas ...
return 1
O código fica mais longo, mas é possível identificar bloco a bloco quais são as condições excepcionais da função em cada bloco.
Lembrem-se que o objetivo aqui não é eficiência e sim a legibilidade e compreensão do código.
Ajustes de if‘s, elif‘s e else‘s
Nessa etapa o objetivo é eliminar o máximo de if‘s, elif‘s e else‘s do código (e adicionar else‘s quando temos algum elif‘s inevitável).
Uma forma de fazer isso é inicializando valores em certas variáveis e só modificá-los dentro do if. Mas nem sempre isso basta e, em alguns casos, quando cada bloco é muito grande ou tem chamadas de funções, etc. sequer é possível de ser feito.
Um exemplo bem simplório só para ilustrar o que estou dizendo:
if cond:
v = f()
else:
v = default
Vira algo tipo:
v = default
if cond:
v = f()
Dessa forma deixo no fluxo normal a condição padrão e crio um branch só para tratar de uma excepcionalidade.
Essa refatoração pode realmente ficar enorme e o resultado também pode ficar pior que o original, logo, use com moderação.
Outra refatoração que faço não tem relação somente com a compreensão do código, mas até mesmo com o funcionamento correto dele: se você tem if e elif é prudente ter um else. Mesmo que seja para levantar um erro. Afinal, se você pensou em mais de um cenário, o que acontece com aquele cenário que você não pensou?
Outra refatoração que ajuda bastante a melhorar a legibilidade do código é conhecida como Extract Method. Ela possibilita trocar um trecho de código por uma chamada de função que descreve o que esse código faz.
Para fazer essa refatoração é bem útil ter uma ferramenta que automatize o processo. A IDE que uso no dia a dia oferece essa refatoração, mas é provável que existam plugins para vários outros editores e IDEs.
Essa é fácil de ilustrar:
def f(x, y):
# Verifica se o objeto x é válido
valid = False
if x.a and x.a == 0:
valid = True
if x.compare(y):
valid = True
if valid:
... faz algo ...
Vira algo assim:
def is_valid(x, y):
if not x.a or x.a != 0:
return False
if not x.compare(y):
return False
return True
def f(x, y):
if not is_valid(x,y):
return
... faz algo ...
Quando você está lendo o código de f(x,y) você, sabe que o objeto x é validado primeiro e o resto da função só será executado quando o objeto x for válido.
Exceções devem ser exceptions
É muito comum ver funções retornando flags (ex. None) quando ela precisa sinalizar um problema, um erro ou uma exceção.
Considerando que idealmente uma função (ou método) deve retornar sempre objetos de um mesmo tipo, o retorno de None deveria ser algo ruim, certo?
Quando retornamos None em nossas funções precisamos ficar verificando todos os valores retornados antes de usá-los, ou seja, toda hora vemos os famigerados:
ret = f()
if ret:
... faz algo ...
else:
... trata o erro ...
Em linguagens com suporte a exceções podemos usá-las para sinalizar problemas ou… excepcionalidades!
try:
ret = f()
exception UmaExcecaoBemEspecificaQueFPodeGerar:
... trata o erro ...
... faz algo ...
Essa refatoração melhora a legibilidade do código porque deixa o tratamento da exceção bem perto do código que pode gerar ela. E para isso ser verdade é importante que o bloco try/except realmente seja pequeno e restrito ao trecho onde a exceção pode acontecer.
Também é importante que a exceção gerada (e tratada) sejam sempre bem específicas para o erro gerado para evitar tratar o erro inadequadamente.
Usar bem a linguagem
O código da empresa onde trabalho é escrito em Python e então eu refatoro ele para ficar mais “pythônico” (o que quer que isso signifique para mim).
Legibilidade é melhor que eficiência nesse momento.
Prefiro um belo “if-zão” bem legível a uma “if–expression” toda muvucada.
Um loop pode funcionar melhor que um comprehension… estou ajustando o código para ler e entendê-lo e não para que ele rode um femtossegundo mais rápido.
Tipos
Tipos (e eventualmente anotação de tipos) podem auxiliar na compreensão do código, bem como as ferramentas de refatoração automática.
Tente padronizar os tipos de parâmetros e retornos das funções. Tente fazer com que eles sempre recebam e retornem objetos dos mesmos tipos. E lembre-se também que None é do tipo NoneType e não do mesmo tipo dos objetos que você está querendo usar. 😜
Uma função que busca uma pessoa pelo nome:
def get_pessoa(name):
pessoas = Pessoa.filter(name=name)
if not pessoas:
return None
return pessoas[0]
Ficaria assim:
def get_pessoa(name: str) -> Pessoa:
pessoas = Pessoa.filter(name=name)
if not pessoas:
raise PessoaNaoEncontrada(name)
if len(pessoa) > 1:
raise MultiplasPessoasComNome(name)
return pessoa
Namespaces para contextualizar
Quando esbarro com muitos nomes que vem do mesmo módulo, tento refatorar o uso deles para incluir o nome do módulo de origem no namespace:
from contants import (
FOO,
BAR,
BAZ,
QUX,
DUX,
)
def f(x):
if x == FOO: ...
if x == BAR: ...
if x == BAZ: ...
if x == QUX: ...
if x == DUX: ...
Vira:
import constants
def f(x):
if x == constants.FOO: ...
if x == constants.BAR: ...
if x == constants.BAZ: ...
if x == constants.QUX: ...
if x == constants.DUX: ...
Dessa forma trago o contexto de qual módulo os identificadores vem.
Métodos próximos dos objetos
Esse faço pouco porque o time onde trabalho não curte “Fat Models” do mesmo jeito que eu gosto.
Mas essencialmente transformo quaisquer funções auxiliares que lidam especificamente com um tipo de objeto em um método do próprio objeto e tiro da frente especificidades que aquele objeto pode encapsular para mim.
Mover trechos de código e funções que lidam com um tipo específico de objeto como método do próprio objeto.
Assim, ao analisar a função etiqueta() foco especificamente em como ela funciona sem me distrair com código de concatenação de nomes.
OOP e não DOP
Dicionários são estruturas de dados tão poderosas em Python que é bem fácil a gente começar a usá-las para tudo em nosso código. Mas isso começa a se tornar um problema com o tempo porque é quase impossível encapsular os dados de um dicionário com o objetivo garantir a consistência deles.
Enquanto estou fazendo a refatoração de um código, começo a usar namedtuples, dataclasses ou até mesmo uma classe “convencional” (com métodos e tudo) para substituir os dicionários que ficam espalhados pelo código.
def grava_pessoa(dados_pessoa: dict) -> int:
if not valida_dados_pessoa(dados_pessoa):
raise DadosInvalidos(dados_pessoa)
# se tem 'id' já existe no DB
if dados_pessoa.get("id"):
return update(dados_pessoa) # retorna o id
return insert(dados_pessoa) # retorna o id
Ficaria mais ou menos assim:
class Pessoa:
def __init__(self, nome, ...):
self.nome = nome
...
def valida(self):
... # valida dados do objeto
def grava_pessoa(pessoa: Pessoa) -> int: # ou Pessoa
if not pessoa.valida():
raise DadosInvalidos(pessoa)
if pessoa.id:
return update(pessoa) # retorna id ou Pessoa()
return insert(pessoa) # retorna id ou Pessoa()
A lógica de validação do objeto não fica me distraindo do que a função grava_pessoa() faz: inserir ou atualizar os dados da pessoa no banco de dados.
TODO/FIXME
Uso comentários TODO/FIXME com dúvidas que não consigo solucionar lendo somente o código que estou mexendo e que não posso esquecer de perguntar para algum colega em algum momento no futuro (lembrem que tenho TDAH e esquecerei as dúvidas que tenho).
# Ignora registro de pessoas afetados pelo bug de migração
if 32000 > pessoa.id > 10000:
return
Provavelmente vira algo assim:
# TODO (osantana): o código abaixo ainda é necessário mesmo
após a migração?
# Ignora registro de pessoas afetados pelo bug de migração
if 32000 > pessoa.id > 10000:
return
Estilo de código
Por último, quando não vejo muita coisa para melhorar no código, eu mudo só algumas coisas menores no estilo de código para forçar algum tipo de formatação pelas ferramentas automáticas de formatação.
# formatador faz algo assim:
x = funcao_com_nome_longo_e_muitos_parametros(
a="foo", b="bar", c="baz", d="qux)
Coloco uma “,” para forçar a indentação abaixo:
# formatador faz algo assim:
x = funcao_com_nome_longo_e_muitos_parametros(
a="foo",
b="bar",
c="baz",
d="qux,
)
Conclusão
Vocês têm alguma outra coisa que você também faça para poder entender algum código mais cabuloso?
Já faz alguns anos que eu estou trabalhando com modelagem de sistemas. Em alguns lugares chamam isso de “arquitetura”, mas uma colega arquiteta (CREA e “talz”) me explicou que não é muito adequado usar a palavra “arquitetura” para definir esse trabalho. Como não sou o especialista e nem estou interessado em me aprofundar nesse tipo de discussão resolvi aceitar os argumentos e não usar mais “arquitetura”.
Minha forma de trabalho é muito intuitiva e baseada em experiências práticas com coisas que deram certo e coisas que não funcionaram bem. Muitas coisas que fiz usando pura intuição se mostraram, mais adiante, como coisas que já existiam e já eram muito estudadas. Só eu é que ignorava.
Estou lendo um livro chamado “Designing Data-Intensive Applications” (Martin Kleppmann) que descreve vários desafios e soluções para desenvolvimento de sistemas distribuídos e conforme vou avançando na leitura vou sendo surpreendido com coisas que eu já fiz sem nem saber que aquilo tinha um nome. 🙂
Nesse artigo eu vou listar algumas técnicas que sempre uso para modelar sistemas em que estou trabalhando. É um ‘braindump’ de técnicas listadas sem nenhuma pretensão, estrutura, ou ordem de importância.
Provavelmente não é uma lista completa também. Uma coisa é ter um repertório de técnicas para usar no dia-a-dia. Outra coisa é lembrar de todas elas para escrever um artigo. Sou péssimo para lembrar das coisas.
As dicas de modelagem que apresentarei abaixo podem ser subdividas em duas categorias: Princípios e Práticas. Vamos dar uma olhada nelas.
Princípios
Os princípios que uso no meu trabalho são mais abstratos e servem para orientar minhas escolhas em um nível de abstração mais alto.
Menos é mais
Quando estou trabalhando na modelagem de um sistema eu gosto muito de limitar minhas ferramentas. Eu trabalho melhor com a restrição do que com a abundância. Eu também gosto de ser um pouco conservador nessa hora.
Um exemplo de conservadorismo e restrição é: se eu preciso oferecer uma API para ser usada publicamente eu provavelmente especificarei uma API HTTP REST. É simples, todo mundo conhece e sabe usar, tem ferramentas infinitas para tudo e é bem elegante.
Outro exemplo desse conservadorismo aparece sempre que eu preciso armazenar dados em algum lugar. As chances de eu escolher um banco de dados relacional (PostgreSQL, é claro 😉 ) para a solução é enorme. Eu escolho SQL porque esse modelo está “por aí” a décadas e tem um número incontável de pessoas usando. E servidores de banco de dados evoluíram absurdamente nos últimos anos.
Se os prazos são um pouco mais apertados (quando eles não são?) eu também escolho ferramentas que eu tenho um domínio maior. Exemplo: se eu precisar desenvolver uma solução distribuída é bem provável que uma linguagem com o perfil de Elixir tenha o ‘fit’ perfeito. Mas eu não conheço Elixir tanto quanto conheço Python. Então é provável que eu vá de Python. Com Django porque eu conheço melhor também.
Se essa escolha se mostrar equivocada (nunca aconteceu) a gente planeja a troca.
Quando chega aquela hora de dizer o nome das ferramentas e tecnologias que vamos usar eu também dou preferência para serviços gerenciados por terceiros à serviços que eu tenha que manter eu mesmo.
KISS
O princípio KISS (Keep It Super Simple*) é bastante antigo e a primeira vez que ouvi falar dele foi quando estava aprendendo a usar Unix. Antes de usar o Unix eu costumava usar o (MS|DR|Novell|PC)-DOS. No DOS, quando eu precisava mostrar o conteúdo de um arquivo eu fazia:
C:\> TYPE README.TXT
Se o arquivo fosse muito grande ele ia rolar a tela até o final e, diferente de hoje onde conseguimos rolar a janela para ver o que aconteceu, não conseguíamos ver o que estava no início do arquivo. Para ver o conteúdo de um arquivo pausando tela por tela a gente fazia:
C:\> TYPE README.TXT /P
E pronto. Notem que o comando TYPE sabia mostrar o conteúdo do arquivo e pausar de tela em tela. Quando passei a trabalhar em um Unix (no estágio) me ensinaram que o comando usado para mostrar o conteúdo de um arquivo era o cat. Então fui lá e mandei um:
% cat README.TXT
cat: README.TXT: No such file or directory
% cat README # ops! aprendendo que o filesystem do Unix é case-sensitive! :)
E então o conteúdo do arquivo despencou a rolar pela tela. Ótimo! Aprendi a ver o conteúdo do arquivo! Agora preciso ver qual o parâmetro para ele parar de tela em tela…
% man cat
… e nada… Pensei: “mas que bela porcaria esse sistema, hein?”. Foi quando o meu supervisor de estágio chegou e falou: “No Unix os comandos fazem só uma coisa. E fazem bem essa coisa. Se você quer pausar a saída do cat (ele falou monoespaçado assim mesmo 😛 ) você precisa jogar a saída dele pro more. Assim ó…”. E digitou:
% cat README | more
Pronto. Depois descobri que essa filosofia era chamada de KISS.
Essa história toda serve para ilustrar o que eu faço quando estou modelando um sistema: tento manter cada componente (seja ele um pacote, classe, microsserviço, etc) muito simples.
Esse princípio também pode ser chamado de “Single Responsibility Principle” (a letra “S” em SOLID). Eles dizem basicamente a mesma coisa mas o “Single Responsibility” formaliza mais o seu significado.
Quando cada um desses componentes é simples e tem uma única responsabilidade eles inevitavelmente serão também mais coesos. E coesão é algo desejável em um bom componente.
Baixo acoplamento e Alta coesão
Um dos melhores livros de programação orientada à objetos que li é o “Fundamentals of object-oriented design in UML” (Meilir Page-Jones). Nesse livro ele bate bastante na tecla de que um bom “objeto” (componente, pacote, etc) precisa ter as seguintes características:
Baixo acoplamento
Se você precisa fazer uma alteração simples em apenas um único comportamento da sua aplicação, quantos componentes diferentes do código você precisa mexer? A resposta para essa pergunta fala bastante sobre o acoplamento da sua aplicação.
O baixo acoplamento é desejável porque ele faz com que sua aplicação fique mais fácil de ser mantida e de ser estendida com novas funcionalidades. O melhor método de se chegar ao baixo acoplamento é por meio do processo de refactoring** constante.
Tentar desenvolver código com baixo acoplamento logo de largada é difícil, demorado, e pode te aprisionar em todo tipo de problema relacionado à early abstraction. Então encare o “baixo acoplamento” como objetivo e não como requisito.
Alta coesão
Esse conceito é um pouquinho mais complicado de explicar, mas o significado do adjetivo “coeso” pode nos dar uma dica. Coeso, segundo alguns dicionários, significa:
Que se relaciona através da coesão, por meio da lógica, de forma harmônica: fala coesa, proposta coesa, atitude coesa.
Intimamente unido; ligado com intensidade.
Disposto de maneira equilibrada, proporcional; ajustada. (figurado)
Seguindo um raciocínio lógico, com nexo; coerente. (figurado)
Sinônimos: coerente, harmônico, ajustado.
Sei que avaliar um componente sob essa perspectiva é muito subjetivo e pode significar coisas diferentes para pessoas diferentes.
Como eu faço isso? Eu olho para o código do componente e procuro por todo tipo de coisa que não deveria estar ali. Pergunto-me porque aquilo não deveria estar ali e penso em algum jeito de mover essa parte para um local mais adequado.
Dividir para conquistar
Na nossa vida de programador a gente está sempre resolvendo problemas. E problemas tem tamanho. Tem problema pequeno, médio, grande, … Resolver problemas pequenos costuma ser (nem sempre é) mais fácil do que resolver problemas grandes.
Por isso um dos skills mais importantes que um bom programador precisa ter é a de dominar a arte de quebrar problemas.
A dica aqui é simples de passar, mas difícil de dominar. Se está difícil resolver um problema:
Pare
Dê uns passos para trás
Olhe para o problema e busque por pontos de quebra
Quebre o problema
Tente resolver uma parte
Se funcionar: profit!
Se não funcionar: volte para o passo 1.
Trabalhei muito com comércio eletrônico ao longo na minha vida e, nesse contexto, sempre encontrei diversos tipos de problemas para resolver. Um desses problemas é: gerenciamento de produtos.
É um problemão… tem questões de marca, especificações, preço, estoque, venda, promoções, kits, recomendações, etc. Não dá para resolver isso tudo de uma única vez e, mesmo se a gente dividir cada uma dessas coisas em várias, os problemas resultantes podem continuar gigantes.
Mas vou falar sobre um fluxo básico: eu sou vendedor (seller) de um canal (channel) de marketplace e cadastro um produto no site para vender. Só que tem outro vendedor que vende o mesmo produto.
Primeira vez que modelei esse problema eu fiz: SellerProduct e ChannelProduct. Tinha uma instância de SellerProduct para cada vendedor com seu respectivo estoque, e preço e um ChannelProduct no canal apontando para um desses produtos de um desses vendedores. A gente dizia que um desses vendedores estava ganhando a “buy box”.
Quando o primeiro vendedor cadastrou o produto ele informou que aquele produto era bivolt. O segundo vendedor falou que esse mesmo produto era 220V. Que informação eu coloco no site? Quem está certo?
Outro problema: o vendedor #1 é de Recife e o vendedor #2 é de POA o preço dos dois é igual e eles têm estoques parecidos. O cliente de Maceió chega no site para simular o valor do frete. É bem provável que o frete do vendedor #1 seja melhor, mas quem ‘ganhou a buy box’ foi o vendedor #2. Como calcular todos os fretes de todos os vendedores e escolher o melhor rapidamente? Perdemos a venda?
Como vocês podem notar a modelagem não está dando conta do recado. Precisamos repensar ela. Talvez a gente precise quebrar esse problema ainda mais.
Nesse processo a primeira coisa que ficou clara para gente é que “Produto” significa muitas coisas diferentes para pessoas e contextos diferentes.
Para o vendedor um produto é “um item no seu estoque”. Ou um “SKU em seu portfólio”. Para uma marca/fabricante/importador um produto é “algo que ele produz com certas características”. Para o canal de venda um produto é “algo que eu estou ofertando”. E para o cliente o produto é “algo que ele compra”.
Entenderam o raciocínio? O super problema “gerenciamento de produtos” precisa ser quebrado em problemas menores:
Gestão de Portifólio (SKU e estoque)
Gestão de Catálogo (características de um produto)
Gestão de Ofertas/Distribuição (anúncios e vitrines)
E cada um desses sub-problemas ainda pode passar por mais um processo de quebra.
Lazy Preoccupation
Esse princípio foi adicionado mais recentemente ao meu repertório. E eu mesmo que dei esse nome (então nem adianta procurar ele na internet 😛 ). Esse princípio deriva da minha experiência de trabalho com metodologias ágeis de desenvolvimento de software.
O princípio da preocupação tardia (lazy preocupation) é: resolve o problema que tem para resolver agora e deixa os problemas futuros para serem resolvidos no futuro.
Parece bobo de tão óbvio (e é), mas é muito interessante ver como eu ainda falho na aplicação desse princípio em certas ocasiões.
A questão aqui é: se você já está trabalhando na solução do menor problema possível (ver tópico anterior) e está funcionando é provável que o mesmo aconteça com os futuros problemas quando chegar a vez deles serem resolvidos.
Quando o futuro chegar, também, é muito provável que sua compreensão sobre o domínio do problema já esteja mais evoluída e solucionar ele fique até mais fácil.
E mesmo nos casos onde isso não acontece e a solução do problema anterior trava a solução do problema futuro é só dar uns passos para trás e tentar outra abordagem. Agora você vai conseguir fazer isso de forma muito mais efetiva porque já tem conhecimentos complementares para te guiar.
Também aplico esse princípio para lidar com questões de modelagem vs. implementação. Quando estou criando a modelagem de um sistema eu tento não me preocupar com características de implementação. Qual banco de dados vou usar? A API vai ser REST ou gRPC? Vou usar serviços ‘serverless’? Isso vai ficar lento?
Esse tipo de preocupação, logo no começo, atrapalha demais o foco no problema e na modelagem na solução abstrata dele. O melhor momento para pensar na implementação da solução é no momento em que você for implementar ela.
Práticas
Abrace as falhas e as hostilidades
Programadores tentam escrever softwares sem falhas. Eles estudam para melhorar suas habilidades e produzir código com mais qualidade. Aprendem a fazer testes automatizados tanto para melhorar o desenho das suas implementações (TDD) quanto para garantir que o software funcione conforme o esperado. O problema está aí “conforme esperado”. O que isso significa exatamente? O que acontece quando um software falha? E quando isso acontece de forma “inesperada”? É possível escrever um software infalível? Não. Não é.
Se não é possível escrever software infalível porque a gente ainda escreve software esperando que o melhor aconteça? E porque a gente tenta esconder essas falhas dos clientes desse software?
Acho que isso acontece porque a gente, como programador, considera a falha de um sistema como uma falha pessoal. Algo que é responsabilidade nossa. “Como eu não pensei nesse cenário? Como sou burro!”, não é mesmo?
Ok… Mas se todos concordamos que é impossível escrever um software porque nos culpamos pelas falhas? Se todo sistema falha não seria melhor aceitar essas falhas de forma mais natural? Expor elas sempre que acontecerem? Falhar o mais rápido possível ao invés de segurar uma situação insustentável por mais tempo e aumentar o estrago?
Quando estou desenhando uma solução eu sempre carrego a premissa de que todos os componentes que estou escrevendo ou usando vão falhar em algum momento.
Resguardar todos esses pontos para garantir de que nenhum dessas partes irá causar um dano muito grande em caso de falha também é muito difícil. Talvez seja fundamentalmente impossível garantir isso (halting problem).
Quanto mais queremos proteger e acrescentar redundâncias e proteções à nossa solução, mais custo e complexidade vamos adicionando nela… o que eu faço então?
Eu sempre projeto sistemas que estejam prontos para continuar funcionando mesmo em cenários de falhas pontuais. Não dá para proteger todos os pontos, logo, se alguns componentes específicos falharem a coisa vai despencar completamente. À esses pontos então eu acrescento uma camada de redundância e uma camada de monitoramento e alertas mais rigorosos. Pronto.
Na minha apresentação sobre a arquitetura de uma das empresas onde eu trabalhei os nossos “Calcanhares de Aquiles” eram:
PaaS (Heroku) – se o Heroku caísse dava bem ruim. Não tinha redundância então era só monitoramento mesmo. Também usávamos o PostgreSQL deles. Mas nesse caso tinha uma fina camada de redundância (dentro do próprio Heroku que não é o ideal).
AWS SNS – se esse falhasse despencava todas as operações ‘online’ da empresa. Só monitoramento.
AWS SQS – se esse caísse a gente perderia dados em um nível muito grave. Então tinha monitoramento e sempre garantia um bom número de workers para esvaziar essas filas.
AWS – Se a AWS inteira caísse… bom… ficaria complicado haha 🙂 Mas nesse caso a Internet inteira estaria com problemas.
DNS – Esse é sempre um problema para a Internet inteira.
Qualquer outra coisa que ficasse fora do ar além dessas causaria alguma degradação ao sistema, mas ele se reestabeleceria com a normalização dos serviços. Tem mais detalhes sobre essa arquitetura nesses links aqui:
Nessa arquitetura, se um serviço falhasse ele retornava um código de falha. Se fosse um erro 5XX era um erro 5XX e ponto final. Não é vergonha retornar um 500 Internal Server Error se de fato um Erro Interno no Servidor (Internal Server Error dã!) aconteceu, oras! Não precisamos “passar pano” para erro de servidor. Se o servidor estivesse fora do ar para manutenção? 503! Se tivesse lento? Timeout! E assim vai.
Quando a gente retornava um erro para o cliente (ex. worker) ele pode decidir como lidar com aquele erro. Tentar outra vez? Descartar a mensagem? Guardar o erro em um log? Não importa. Ele vai saber que aquela operação não aconteceu. Agora imagina se o servidor falhou na operação e retornou um 200 Ok dizendo que tá tudo sobre controle?
Então abracem as falhas. Os erros. Tratem seus serviços como falíveis e vocês vão sempre desenhar soluções mais robustas.
Idempotência é sua amiga
Eu disse no tópico anterior que se aconteceu uma falha no seu serviço você tem que deixar isso claro para seu cliente, certo? Mas não custa nada dar uma mãozinha para ele se recuperar dessa falha depois.
Vamos supor que tenho um worker que pegou uma mensagem de uma fila e precisa mandar 15 requests para uma API baseado nessa mensagem. Ele manda o primeiro e “ok”. Manda o segundo e… “ok”. Manda o terceiro e “ERRO!”. Tento mandar o quarto e… “ERRO!” e assim vai até o fim.
O que eu faço com os requests que falharam? Tento outra vez? E se continuarem a falhar? O que eu faço?
Em teoria você precisaria de um lugar para “anotar” quais requests falharam e quais tiveram sucesso em algum lugar para retentar só aqueles requests que falharam? Mas o worker não guarda estado. Ele só pega mensagem de uma fila e procede com os requests.
Criar um sistema só para guardar os requests que precisam ser feitos é muito complexo. E se esse sistema também ficar fora do ar? Entenderam o drama?
Pois bem. Fizesse a tal API ser idempotente? Se você repetir um request que já aconteceu antes ela responderia algo tipo: 304 Not Modified ou 303 See Other (que são 2 códigos HTTP de sucesso?).
Se sua API for implementada desse jeito o seu worker pode falhar completamente a transação (devolvendo a mensagem para a fila) porque quando ele precisar repetir essa operação ele vai repetir exatamente os mesmos 5 requests. E nenhuma informação vai ficar duplicada ou faltando do lado da API.
Tente sempre fazer com que suas interfaces privilegiem operações idempotentes (mesmo que para isso precise fazer umas concessões aos padrões de POST e PATCH).
HTTP é rei e a Web é uma API
Duas das coisas mais difíceis em computação, para mim, é dominar a arte secreta de se escrever bons protocolos e boas linguagens de programação. Só os grandes gênios da computação conseguem fazer isso bem feito.
Um dos protocolos mais elegantes que já vi é o HTTP. Ele é simples, poderoso, compreensível, escalável, bem conhecido e tem ótimas implementações disponíveis para todo mundo.
Com a explosão no surgimento de APIs REST foi possível mostrar que o protocolo HTTP, por si só, permite implementar um número gigantesco de soluções mesmo sendo um protocolo muito básico com apenas um punhado de métodos (GET, POST, PUT, PATCH, DELETE, etc).
É isso mesmo: APIs REST tem somente esses métodos definidos por RFCs. Então aqueles ‘verbos’ nas URLs (ex. /user/subscribe) da sua API são, no mínimo, uma licença poética 🙂
O que eu acho interessante nessa “limitação” é justamente isso: ela me força a refletir melhor sobre os objetos (ou documento, ou resource, ou …) expostos na minha API. É uma limitação que me força a pensar uma solução que consiga funcionar na simplicidade do protocolo.
Coisas como gRPC abrem esse leque de opções absurdamente e, apesar de facilitar o desenvolvimento e a entrega do produto final, exige muita cautela por parte do desenvolvedor para não criar um monstrengo de API com dezenas de métodos diferentes. E é aqui onde a gente reafirma o princípio do “Menos é mais” que listei lá em cima. Já interfaces com GraphQL tem um propósito muito específico: navegar por graphos e não deveriam ser abusadas para outros usos (até porque APIs GraphQL usam o protocolo HTTP de forma bem… estranha…).
Na minha apresentação “A Web é uma API” eu ilustro alguns conceitos que demonstram como a Web já é uma API inerentemente REST e no Toy, um framework de brinquedo, eu experimento esse conceito:
Event Sourcing é um modelo de arquitetura de software que casa super bem com o princípio da Lazy Preocupation e com o princípio do Menos é mais. Adotar esse modelo também permite que a gente trabalhe com APIs mais “burras” (simples/KISS) e, como veremos adiante, isso é desejável.
Em arquiteturas mais “tradicionais” é comum à um serviço comandar operações, ou seja, o serviço determina e chama as operações que precisam ser executadas indiferentemente de uma sequência específica (sync) ou não (async).
Um sistema que de gerenciamento de pedidos de um site de comércio eletrônico, por exemplo, ao receber um novo pedido, precisa gravar esses dados em um banco de dados, mandar um e-mail para o consumidor para confirmar o recebimento do pedido, avisar o sistema de fulfillment que tem um pedido novo que precisa ser preparado, etc, etc.
Note que nesse modelo o sistema de gerenciamento de pedidos precisa distribuir todas essas tarefas para sistemas externos e isso cria uma dependência de todos esses sistemas no sistema de gestão de pedidos.
Imaginemos que, no futuro, esse mesmo sistema de pedidos precise executar uma operação que envia os dados desse pedido para um novo subsistema de BI. Você vai implementar/implantar esse sistema de BI e vai ter que tambémadicionar uma chamada para ele no sistema de gestão de pedidos. Notaram o acoplamento aparecendo aqui?
Em uma arquitetura baseada em eventos (event sourcing) o sistema de gestão fica responsável apenas por registrar o novo pedido e avisar que tem um “pedido novo” à quem possa interessar publicando esse evento em um tópico (ou subject) de um barramento de mensagens (publish).
Se um sistema de fulfillment tem interesse nesse novo pedido (bem provável) ele só assina (subscribe) o tópico sobre novos pedidos e faz o que tem que ser feito em cada novo pedido.
Usar um sistema de filas persistentes para assinar esse tópico é bastante prudente porque facilita o processamento desses eventos mesmo em cenários de falhas de workers ou instabilidades.
Quando o nosso sistema de BI estiver implantado é necessário apenas conectar ele ao sistema de pedidos através de outra assinatura ao tópico de novos pedidos e, desse modo, o sistema de gesrenciamento de pedidos nem precisa tomar conhecimento desse novo sistema. É só disparar e esquecer. Fire and Forget.
APIs burras e autônomas, workers espertos e dependentes
Para que a gente considere uma API HTTP boa ela precisa apresentar um conjunto muito grande qualidades. Características como robustês, estabilidade e performance são só algumas dessas qualidades.
Quando uma API tem muitas responsabilidades e faz muitas coisas é bem provável que sua complexidade cresça demais e entregar essas qualidades começam a se tornar um desafio bem grande.
E se as APIs delegassem essa complexidade para outros agentes da arquitetura? E se elas fizessem menos coisas? E se elas fizessem só o básico de validação de dados, armazenassem os dados que precisam ser armazenados e avisassem que essa operação aconteceu?
Uma API que sabe validar, guardar e notificar o que aconteceu entrega tudo o que uma API precisa fazer. Mas ela precisa ser capaz de fazer isso sozinha. Se a validação de uma informação precisar de algum dado externo esse dado precisa ser “injetado” nessa API. Mesmo que isso cause uma duplicação (desnormalização).
Se a função de uma API se restringir à essas 3 operações fica muito fácil implementar uma API simples, rápida, robusta e estável porque o código dela será muito simples. Quase nenhuma regra de negócio incorporada ao seu funcionamento.
As regras de negócio mais complexas podem ficar em workers que estarão processando os eventos de uma fila (que assina um tópico) e terão todo o tempo do mundo para aplicar essas regras, fazer consultas em outras APIs, e gerar um resultado que será postado em outra API, na API originária, ou até mesmo em um tópico do barramento de mensagens.
Idealmente um worker deve gerar uma única saída (ex. POST) para cada evento de entrada. Essa regra só pode ser violada nos casos onde a API que receberá essas saídas múltiplas for idempotente. Caso contrário você pode ter problemas com duplicação de registros.
Deixe as decisões para quem detém mais contexto
Quando a gente aplica o princípio da Lazy Preoccupation é bastante comum perceber que quanto mais um fluxo de processamento se adentra pelo sistema, mais informação de contexto ele carrega.
Isso significa que quando você recebe uma entrada no sistema ela tem apenas os dados informados ali. Conforme esses dados vão passando por outros sistemas ele pode ser enriquecido com informações adicionais e essas informações adicionais são muito úteis para tomar decisões importantes no fluxo das suas regras de negócio.
Então evite ao máximo lidar com problemas complexos logo no início dos fluxos. Se tá difícil resolver um problema em um determinado ponto desse fluxo é melhor deixar ele adentrar um pouco mais (lazy preoccupation) para que ele absorva mais dados de contexto que podem ajudar nas suas decisões relacionadas às regras de negócio.
Interfaces e protocolos guiam implementações
A sigla API significa “Application Programming Interface” e a palavra importante aqui é “Interface” em contraponto à palavra “Implementation”. Alterar implementações é fácil. Alterar interfaces não.
Quando eu altero uma implementação difilcilmente eu quebro um sistema. Mas se alteramos uma interface é quase certo que teremos problemas.
Então, ao desenvolver um sistema novo, dedique bastante tempo nessa etapa. Técnicas como TDD ajudam você a transitar por esse estágio quando não conhecemos muito bem o domínio do problema que estamos lidando.
Comece a implementar o sistema somente depois que você estiver confortável com o desenho das interfaces e modelos expostos por ela.
Append-only for the rescue
Os sistemas modernos que operam em uma escala muito grande invariavelmente precisam ser implementados usando modelos distribuídos e, em sistemas distribuídos, você vai acabar tendo que lidar com locks e implementações de mutexes. Muitas vezes o seu banco de dados é quem vai ter que dar cabo dessas operações mas o fato é que os locks e mutexes estarão lá para ferir a performance do seu sistema.
Uma forma de diminuir (e até mesmo evitar) algumas dessas travas é substituir operações de update por operações de insert no seu banco de dados. Quando atualizamos um registro em uma tabela o banco de dados vai ‘travar’ esse registro para escrita bloqueando outras transações que queiram fazer o mesmo***. Isso pode penalizar severamente a performance do seu sistema. Para o banco de dados, fazer um insert, é muito mais simples e as ‘travas’ vão ser usadas somente para atualização de índices.
Mas isso tem um custo muito alto no processo de recuperar essas informações. No lugar de recuperar apenas um registro do banco de dados você precisa buscar todas as operações relacionadas àquele registro e consolidar elas para obter a informação necessária. Muito ineficiente.
Para amenizar essa ineficiência é possível utilizar o design patternCQRS (Command and Query Responsibility Segregation) que segrega as responsabilidades de escrita e leitura em dois segmentos diferentes do seu banco de dados permitindo escritas rápidas que serão ‘projetadas’ assíncronamente em um registro consolidado para consulta futura.
Notas
* Hoje traduzem esse acrônimo como “Keep It Super Simple” por causa da carga ruim que a palavra “Stupid” da tradução original (Keep It Simple Stupid) carrega.
** Refactoring é aperfeiçoar um pedaço do seu código sem alterar seu comportamento. O que garante que esse comportamento não está sendo alterado é um conjunto de testes automatizados. Ou seja, se não tem teste automatizado ou se o comportamento do software muda não é um refactoring. Se acontecer de algum teste quebrar durante um refactoring é interessante tentar entender se isso acontece porque seu código está mal implementado (ex. testando mais a implementação do que o comportamento) ou se a mudança está realmente mudando o comportamento do código. Vamos usar as palavras corretas para refactoring e para reescrita.
*** Esse assunto é um tanto mais complexo que isso e recomendo a leitura do livro “Designing Data-Intensive Applications” (Martin Kleppmann) para mais detalhes sobre esse assunto.
Dia desses vi um tuíte onde uma pessoa contava que estava tendo dificuldades em aprender Programação Orientada a Objetos (POO ou Object-Oriented Programming – OOP) mesmo depois de já ter estudado bastante. O tuíte me fez lembrar que também foi difícil no meu caso.
Se tem um assunto que me fascina é o aprendizado de computação. Nunca trabalhei com isso e nem sou um especialista mas sempre estou pesquisando sobre o assunto. Gosto desse assunto porque aprender computação sempre foi algo prazeroso pra mim e gostaria de entender porque isso acontece com algumas pessoas e com outras não. Queria saber se seria possível ensinar computação de um jeito que os aprendizes tivessem essa mesma sensação e esse mesmo tipo de emoção.
Mas com o tempo fui entendendo que as pessoas são muito diferentes e a forma com que cada uma delas encara diferentes tipos de aprendizados também varia muito. Pode até ser possível personalizar uma experiência para uma pessoa mas certamente esse método não funcionaria com outra.
Eu mesmo… sou péééssimo para aprender idiomas. E não é que eu não goste de estudar e aprender… é só que eu tenho que lutar muito mais que outras pessoas para avançar só um pouco. Cheguei até a achar que eu era só um “burrinho esforçado” mas hoje entendo que não existe gente burra. Tá… Pensando bem… Tem algumas que são burras sim… mas não é esse o ponto desse texto 🙂
Mesmo na computação tem assuntos que me exigem mais do que outros para aprender. Por exemplo: aprender uma nova linguagem de programação em um paradigma que eu já conheça é super rápido. Como já tenho referências de outras linguagens é basicamente construir paralelos entre umas e outras: “Ah! A sintaxe do Java parece com a sintaxe do C/C++.” ou, “Essa parte entre colchetes do Objective-C lembra um pouco do Smalltalk”, e assim por diante.
Mas quando é pra aprender um novo paradigma de programação, meu amigo, a coisa empaca muito. Já faz uns bons anos que bato na trave para aprender uma linguagem funcional mas não sai. A última “vítima” dessa tentativa foi Elixir. A linguagem parece incrível e me deixou super empolgado, mas… não evolui.
E sabe de uma coisa? Está tudo bem. Hoje eu tenho maturidade para entender que uma hora ou outra sai. Porque foi assim que aconteceu quando dediquei tempo para aprender Programação Orientada a Objeto.
No começo era o BASIC
Nos anos 80, algumas crianças privilegiadas como eu, tiveram contato com os primeiros microcomputadores que apareceram no mercado brasileiro. Eles se tornaram “acessíveis” (bota aspas nisso…) para a população e eram vendidos, para os pais, como ótimas ferramentas de aprendizado para os seus filhos. Era a ferramenta perfeita para tirar o gênio da cabeça das crianças.
Já para as crianças elas eram perfeitos videogames que ofereceriam horas e mais horas de diversão. No meu caso foi um pouquinho diferente: eu queria jogar meus próprios jogos e para isso eu precisava aprender a programar. E então tudo começou.
Essas máquinas vinham quase sempre com algum dialeto de BASIC para programar. E como essas máquinas eram lentas e limitadas qualquer código BASIC rodava na velocidade de uma tartaruga. Com freio de mão puxado. E por isso meu sonho de criar meu jogo foi sendo postergado… e postergado… e…
O jobzinho…
Certo momento da vida apareceu uma oportunidade para trabalhar como programador em uma imobiliária. Comecei o desenvolvimento em BASIC mesmo mas logo tive contato com uma linguagem mais apropriada para desenvolvimento de software empresarial: Clipper (Summer’87).
A linguagem Clipper era meio diferentona… não tinha número de linha nos programas. Não tinha comando GOTO para desviar o fluxo da execução… mas aos trancos e barrancos eu fui aprendendo…
Engraçado lembrar que eu achava ela uma porcaria porque não tinha GOTO e me obrigava a ficar fazendo loop dentro de loop dentro de loop com flag1, flag2, flag3, … pra controlar a execução. Imagina a maçaroca que era esse código (por isso você não deve se culpar por fazer código ruim quando está aprendendo…).
Logo depois desse trabalho eu tive contato com a linguagem Pascal e passei a focar mais em usar ela porque ela permitia desenvolver software gráfico (uma limitação do Clipper que só permitia gerar gráficos com bibliotecas proprietárias externas).
Foi só quando aprendi Pascal que também aprendi que esse paradigma de programação que eu estava usando desde o Clipper se chamava “Programação Estruturada”.
Foi também através do Pascal que tive meu primeiro contato com um paradigma “novo” que iria “revolucionar a forma de escrever software”: a Programação Orientada a Objetos.
Lembrem: eu era um brasileiro, morava no interior, não sabia nem o que era Internet, etc. As únicas fontes de informações que a gente tinha do mundo da informática eram as revistas, os livros e os ‘pirateiros’, profissional que conseguia as ‘cópias do original’ dos softwares que a gente usava. Ah! E software pirata sem manual! 🙂
O Turbo Pascal que a gente usava vinha com um negócio chamado “Turbo Vision” que era implementado com classes e objetos e permitia criar janelas em tela texto e usar com o mouse. Era bem massa… mas eu não conseguia usar porque não sabia direito nem o que era um “objeto”.
Como as revistas só falavam dessa tal POO e eu não conseguia entender nem usar eu até comecei a pegar “ranço” do troço. E eu tentei (o primeiro código OO que escrevi sobreviveu e está aqui. Era uma interface para usar mouse no DOS).
Mas não avancei daí mais. Pra mim, naquela época, objeto era um “struct com função dentro” (ou um “record com função dentro” pra quem prefere Pascal).
Nessa época eu até comprei um livro sobre programação OO mas desisti da leitura logo no começo porque não estava entendendo nada. Guarde essa informação.
Avança a fita e pula uma parte…
Depois disso eu decidi sair da profissão de programador e deixar a programação mais como hobby e investi meu tempo e aprendizado em coisas de mais baixo nível. Foi quando aprendi C, Assembly, comecei uma BBS, fiz estágio com Unix, mexi com Linux, etc…
Então tudo mudou novamente e fui trabalhar com Linux na Conectiva (com C) e conheci Python.
Python pra que te quero
Eu ainda pretendo escrever sobre a guinada que a linguagem Python proporcionou na minha carreira então vou economizar aqui.
Quando aprendi Python e usei ele em um projeto fui me acostumando cada vez mais a programar usando objetos. Mas só aprendizado prático mesmo: como criar uma classe, como criar “objetos” (o nome certo seria instância) dessa classe, etc. Criava aquele programão estruturado tudo dentro de uma classe só e tal… mas o código funcionava e as entregas eram feitas.
Lendo mais sobre Python e estudando mais Python eu acabei sendo exposto a mais e mais código orientado a objeto. E fui aprendendo, de forma orgânica, a programar assim.
A melhor forma de estudar programação é lendo programas. A melhor forma de aprender a programar é programando.
eu mesmo
Eu ia desenvolvendo código OO intuitivamente e por ‘imitação’ do código dos outros e, em paralelo a isso, os livros que eu passei a consumir iriam deixar de ser livros sobre “Python” e passariam a ser livros sobre “Programação Orientada a Objetos”. Como livro é caro eu decidi dar uma chance para um livro que eu já tinha comprado muitos anos atrás: Fundamentos do Desenho Orientado a Objeto com UML – Meilir Page-Jones.
Aquele livro que não fazia o menor sentido pra mim no passado consolidou todo aquele repertório que aprendi de forma orgânica programando em Python e “magicamente” a programação OO passou a fazer total sentido pra mim.
A partir desse ponto minha carreira profissional teve várias turbulências e tive que trabalhar com Java (detestei) e com Smalltalk (adorei), duas linguagens que também são OO e que possuem uma comunidade com bons fundamentos nesse paradigma. Ou seja, aprendendo e trabalhando com essas linguagens fui enriquecendo ainda mais a minha experiência nesse paradigma.
Quando trabalhei com Smalltalk li outros livros importante pra mim mas que não são específicos para POO:
The Object Primer – Scott Ambler (esse eu gostei menos)
Seria interessante acrescentar um livro que ensine POO junto com uma linguagem à essa lista também. Mas isso varia muito de linguagem para linguagem então o melhor é perguntar entre os profissionais de cada uma delas qual é o livro mais indicado.
Precisa ler tudo isso pra aprender POO? Certamente que não. Eu diria até que alguns desses livros nem fazem bem para quem está começando. O que é importante mesmo é:
Ler muito código OO
Programar muito código OO
Ler uns livros, artigos, etc nas horinhas vagas
Descansar bem e cultivar uma vida saudável
Outra coisa que é muito importante reforçar também é que nem sempre o que serviu pra mim vai servir pra você. Se não estiver funcionando, tenha calma, dê um passo para trás, e tente outra abordagem. Tenha paciência com você mesmo e não desanime. O caminho tá cheio de frustrações para serem superadas.
E me desejem sorte… vou ali tomar mais um pouco de surra do paradigma funcional do Elixir…
Quando eu comecei a trabalhar com computação o mercado contratava Digitadores, Programadores e Analistas de Sistemas. Os digitadores só digitavam e os programadores só programavam os sistemas especificados por um “Analista de Sistemas”. Esse era “O Cara”.
Como vocês podem ver a divisão do trabalho e responsabilidades era bem diferente do que temos hoje. Hoje temos umas divisões meio esquisitas tipo “backend” e “frontend” e um eixo, e divisões bem nebulosas como “Júnior”, “Pleno” e “Sênior” em outro eixo. Tem uns caras que correm por fora também: “devops”, “architects”, “leaders”, …
Na mesma época em que comecei a trabalhar também já estava rolando um movimento onde contratavam os “Analistas Programadores”. Um cara que sabia fazer a análise de sistemas e a programação. Obviamente, como vivemos em um sistema capitalista, o salário desse profissional nunca era a soma dos salários de um programador e de um analista. Tipo um programador ‘fullstack’ recebendo salário de ‘front’ ou ‘back’. Precarização nunca foi um assunto novo.
Mas essa introdução toda é só pra falar que quando estudei Processamento de Dados (outro termo que foi caindo em desuso junto com CPD) em uma ETEC eu tinha uma matéria chamada “Análise de Sistemas”.
Naquela época eu já trabalhava com programação então eu matava boa parte das aulas para aperfeiçoar minhas técnicas em coisas importantes como jogar Truco. Com certeza valeu a pena.
Mas as aulas de “Análise de Sistemas” do professor Peccini eu fazia questão de assistir. Queria assistir porque logo nas primeiras aulas ele falou coisas bem intrigantes sobre “Sistemas”.
Prof. Peccini
Uma das coisas que ele disse foi que “Sistemas” não tem uma relação direta com computadores. Sistemas sempre existiram e sempre vão existir. Com computadores ou sem eles.
O trabalho de um analista de sistemas, então, com o perdão da redundância, é analisar esses sistemas e, eventualmente, propor mudanças. Que tipo de mudanças? Mudanças que possam tornar os sistemas mais eficientes ou até mesmo extinguir eles completamente. Automatizar certos sistemas com o uso de computadores é apenas um tipo de mudança em um grande universo de possibilidades.
Ele também falava coisas como “Você não transforma um sistema ruim em um sistema bom colocando computadores e automatizações nele”. Ele falava que fazer isso era só “automatizar a burocracia”.
Temos vários exemplos disso em nossa vida. Basta ir em um cartório e ver quantos computadores eles tem lá dentro.
Naquela época a gente era jovem e adorava ficar de frente para o computador “codando” as coisas. Mas as aulas do Prof. Peccini eram na sala de aula normal. E ele dava coisas em papel pra gente estudar.
Modelagem de Dados
Algumas coisas que o Prof. Peccini ensinou pra gente é modelagem e normalização de tabelas.
Isso é uma folha do talão de pedidos. Espécie de antepassado do “carrinho de compras”
Em uma das aulas ele pegou um “talão de pedidos” que ele tinha comprado em uma papelaria e levou para a sala de aula. Ele ia destacando as folhas do talão e entregando para cada um dos alunos da turma.
Depois que cada um de nós tinha uma folha dessas ele disse: quero que vocês criem uma ou mais tabelas no dBase III Plus (outro professor já tinha ensinado isso em outra matéria) para guardar informações de pedidos.
Muitos alunos da turma modelavam apenas uma tabela e repetiam os dados comuns em todos os registros. Não julguem! É um curso onde as pessoas estão aprendendo as coisas. Lembrem que o normal é não saber o certo até que se aprenda.
Eu, como já disse, por já estar trabalhando na área, fiz a minha modelagem certinha (pequeno ajuste aqui e ali). Mas confesso que fazia essas coisas por pura intuição.
O professor então revisou os trabalhos com cada aluno e foi dando as orientações necessárias para cada um deles pensar em melhorias. Ele só dava dicas e fazia perguntas para os alunos. Os próprios alunos acabavam chegando à modelagem mais adequada. Depois desse exercício ele corrigiu tudo e deu notas (boas) pra todo mundo.
A partir daí ele deu algumas aulas com exercícios mais convencionais sobre “normalização” de tabelas e usava sempre os erros iniciais dos alunos para ilustrar cada uma das técnicas de normalização.
As aulas eram incríveis. Melhor que as melhores partidas de Truco que disputei na escola.
Dicionário de Dados
Antigamente os analistas de sistemas produziam muitos documentos sobre… sistemas. Um desses artefatos era o Dicionário de Dados.
Um dicionário de dados servia para dar nomes, tipos, descrição e outras informações sobre entidades, relacionamentos, atributos, propriedades e domínio dos negócios.
Era um troço chato pra cacete de produzir. Mas era um ótimo exercício para “dar nome aos bois”. Servia para desambiguar nomenclaturas e chamar as coisas certas pelos nomes certos.
Ele dizia que se tá difícil achar bons nomes para algo ou se tinha duas coisas diferentes com o mesmo nome isso era um sintoma de problema no sistema.
Ele também falava que dar o mesmo nome para coisas diferentes em contextos ou com perspectivas diferentes era “ok”, mas o dicionário de dados devia deixar explícito esses contextos e perspectivas.
Exemplo disso? A palavra de “Produto” tem significados diferentes para o estoquista, pro operário da linha de montagem, pro profissional do marketing, etc. Em um sistema que envolva todos esses atores é importante mapear todos esses usos e significados.
Recentemente, no trabalho, um amigo citou um outro professor (Prof. Imre Simon da USP). Segundo esse amigo o Prof. Imre havia dito algo como “Um dos grandes problemas da computação é dar nomes diferentes para a mesma coisa e dar o mesmo nome para coisas diferentes” (não encontrei a citação original, então, me perdoem por eventuais equívocos).
Na primeira edição do livro eXtreme Programming do Kent Beck e no livro Domain-Driven Design do Eric Evans também se fala um pouco sobre esse nivelamento de termos usando o conceito de metáforas de sistema (System Metaphor). Isso mostra que comunicar um sistema é um problema bastante antigo mas ainda presente e importante para o nosso trabalho.
Modelagem de Sistemas em Software
Se tem uma coisa que faço bem é modelar sistemas em software. Não consigo explicar porquê e nem tenho plena consciência do que eu faço para executar essa tarefa tão bem. A coisa simplesmente acontece. Acho que é o que chamam de “intuição”.
Não sou infalível e já cometi muitos erros nessa tarefa. Mas na mediana eu tenho um saldo positivo.
Sonho em, algum dia, ter uma consciência maior sobre o processo que acontece no meu cérebro quando estou modelando um software. Gostaria muito de escrever e ensinar isso para outras pessoas igual o Prof. Peccini fazia.
Mas enquanto isso não acontece eu vou falar uma coisa ou duas aqui que eu acho que fazem parte desse conhecimento.
Quando o professor falou que sistemas existem independentemente de computadores ele destravou algum circuito no meu cérebro que me permite observar um sistema funcionando e então partir desse sistema para guiar a minha modelagem. Independentemente de falhas e ineficiências ele é um sistema que já está sendo usado.
Então eu sempre começo a modelar um sistema de software partindo do sistema real. Esse processo inclui a modelagem de dados, processos e o dicionário de dados.
Aí eu lembro que o professor falou que colocar um software que reproduz problemas e ineficiências de um sistema é meramente “automatizar a burocracia”. A imagem de um cartório invade minha mente e eu inicio a busca por problemas, ineficiências e o que eu chamo de “armadilhas de modelagem”.
Quando estamos modelando um sistema de software é bastante comum olhar para outros sistemas similares como referência (benchmark) e é bem comum a gente cair em armadilhas nessa brincadeira. Vou dar um exemplo.
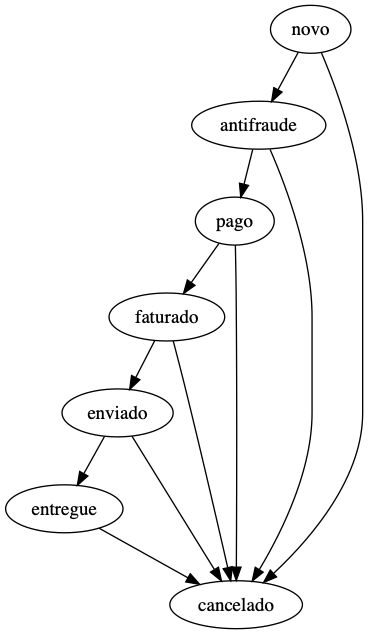
Uma vez (mentira… foram várias) precisei modelar um sistema de gestão de pedidos para um site de e-commerce. Pedidos nascem quando você finaliza sua compra e, geralmente, possuem um workflow que é implementado com uma máquina de estado. Então o pedido transiciona de “novo” para “pago” e para “faturado“, “enviado“, “entregue“, etc. Tem o estado “cancelado” também. Quase todo mundo modela assim e aí vários problemas começam a acontecer.
Você percebe, por exemplo, que a gente não “envia um pedido”. A gente “envia pacotes com produtos pedidos”. Onde o estado “enviado” (e o “entregue”) deveria estar? No pedido? No “pacote”? A solução correta depende muito do significado de cada modelo de negócio. Mas a mensagem aqui é: pare para pensar no que acontece na vida real antes de colocar isso no seu software.
Outro exemplo nesse mesmo sistema: cancelamento. Quando você para pensar na vida real você percebe que um pedido pode ser cancelado a qualquer hora. Pelo código de defesa do consumidor o cliente poderia cancelar esse pedido até 7 dias depois que o produto chegou na casa dele. Então a máquina de estado (bem simplificada) ficaria mais ou menos assim:
Parece certo isso? Não, né? Ah! E as ações para cancelar um pedido variam dependendo da etapa em que ele foi cancelado. Imagine a complexidade disso.
E se a gente quiser implementar o conceito de suspender um pedido sem cancelar (para conversar com o cliente sobre alguma dúvida que ele tenha)?
Você vai modelar um sistema de gestão de pedido e quando olha em volta todo mundo modela mais ou menos desse jeito. É muito fácil cair nessa armadilha. Eu mesmo caí várias vezes.
Talvez, e só talvez, “cancelado” não seja um estado dessa máquina de estado? Será que não poderíamos usar outro workflow/máquina-de-estado para gerenciar suspensões e cancelamentos?
Outra armadilha no mesmo domínio de negócio tem relação com os termos usados para se conversar sobre o sistema. Uma frase como “Vou colocar o produto pra vender no site” pode induzir o analista de sistemas a criar uma entidade Product no site de comércio eletrônico quando na verdade você não tem um produto de verdade lá. O que a gente tem em um site de comércio eletrônico são anúncios de itens (SKUs – Stock Keeping Unit) de um produto (GTIN/EAN/ISBN) produzida por uma marca.
Entendem o problema que a ambiguidade da palavra “produto” pode trazer pra sua análise?
Óbvio que eu caí nessa armadilha inúmeras vezes. Honestamente eu caí nessa armadilha *todas as vezes* que tentei modelar esse software.
Então… esse casos servem para ilustrar, na prática, algo que acontece intuitivamente no processo de análise de sistemas que eu faço. Como não consigo fundamentar essas explicações eu espero que os exemplos ajudem vocês de algum modo.
É certo que tem mais técnicas e processos que eu uso e conforme eu for tomando consciência deles vou tentar trazer aqui pra vocês.
Hoje eu vi uma pesquisa na internet onde perguntavam como eu me sentia quando via meu código sendo removido por outros desenvolvedores do meu time.
A pesquisa também pedia informações de perfil profissional para tentar entender se profissionais com experiências diferentes reagiriam da mesma forma ao verem seu código removido por outro desenvolvedor do time.
A primeira coisa que pensei foi sobre o assunto foi “depende”. O software continuou funcionando direito depois do “facão”? O código perdeu alguma característica importante?
Sempre que vou revisar um código e vejo um patch que remove muitas linhas a minha primeira reação é de empolgação. Então, por padrão, eu costumo gostar muito de alterações que removem código. Nesse momento eu não sei se o código removido é meu ou não então eu também posso dizer que a autoria do código é indiferente pra mim. Sou devoto da igreja do Collective Code Ownership.
A partir daí eu sigo com a revisão usando outros critérios para validar o que está sendo feito. E é aí que o “depende” entra em ação e eventualmente tenho dúvidas sobre ser favorável ou não à remoção deste ou daquele código.
Código desnecessário
Se o código removido não está mais sendo usado obviamente tem que ser removido. Todo mundo ganha com isso. Aquela API antiga que não tem mais suporte e ninguém usa mais? Apaga. Foi tarde.
Outro tipo de código desnecessário são aqueles trechos que estão comentados dentro dos arquivos. Se você usa um sistema de controle de versão (e deveria) jogue fora isso. Não comente código “pra usar depois”. Se você precisar usar depois busque no controle de versão e use.
Código grande
Algumas vezes a gente vê algum método muito grande e decide melhorar a implementação dele. Como conseqüência o código termina menor do que o anterior e os testes ainda continuam passando. Ou seja, foi uma boa refatoração onde todos ganham.
Mas… tem uma exceção para isso aqui. A legibilidade. Imagine que você tem um código tipo:
for i in range(50):
for j in range(50):
double[i][j] = array[i][j] * 2
Aí a refatoração faz isso:
double = [[array[i][j] * 2 for j in range(50)] for i in range(50)]
Claramente é um código mais curto e roda mais rápido. Mas e a legibilidade? Para julgar se essa redução no código é boa ou não precisamos avaliar mais aspectos.
Pra mim, por padrão, esse tipo de remoção de código é um “não”. Mas o desenvolvedor pode me convencer do contrário se dizer algo como “cara, esse método é crítico e essa mudança melhora em 30% a performance dela”.
Código complexo
Alguns programadores (eu aqui!) tem uma tendência de adicionar complexidades desnecessárias no código para tornar ele mais extensível, mais eficiente, etc. Não é muito incomum que um programador precise resolver um problema muito específico com um código bem básico saia criando sistemas de plugins ou configurações em busca de mais flexibilidade.
Por sofrer desse problema não é incomum que eu receba modificações que passam facão geral nessas partes do código que eu tinha escrito.
Sendo bem franco? Eu fico chateado. Mas depois que passa a tristeza e a razão assume o controle é possível entender que a mudança é potencialmente positiva.
Um “causo” (sem desfecho)
Certo momento da minha vida eu pegava muito freela pra fazer. Uma empresa me contratou para desenvolver um software de simulação de empresa para um cliente deles.
O cliente deles tinha um curso de administração e empreendedorismo e criou um simulador de empresa usando Excel. É. Recebi uma planilha com cerca de 30 abas (não é uma hipérbole) onde você controlava estoque, verba de marketing, salários, de uma empresa hipotética e a planilha ia “reagindo” a essas mudanças e mostrando a evolução do seu negócio.
Eu ia levar 1 mês só com a engenharia reversa daquela planilha para então começar a criar uma aplicação Django pro cliente do meu contratante (Django era requisito do meu cliente).
Então pensei: e se eu implementar um motor de planilha no Django? Criaria o motor, faria “copy & paste” das fórmulas da planilha para o banco de dados da aplicação e profit!.
Era uma ideia meio ousada e, por isso, fiz uma prova de conceito para mandar pro meu contratante avaliar. Ele apagou tudo e substituiu as fórmulas da planilha por código Python tradicional. Ele refez o que eu tinha feito só que hardcoded.
Obviamente, como era só uma prova de conceito com um subconjunto bem pequeno da planilha, o meu “motor” era bem maior do que um conjunto hardcoded de condicionais. Na minha solução o cliente (treinado) poderia ajustar os parâmetros e fórmulas da simulação. Na versão nova só um desenvolvedor poderia fazer isso.
A alteração feita reduziu muito o código em troca de flexibilidade e de fato ficou bem mais simples e fácil de compreender. Mas foi um bom negócio? Não sei. O cliente deles desistiu do projeto por questões financeiras e nunca soubemos qual abordagem seria melhor.
Esse caso mostra bem como eu tenho uma forte tendência ao over-engineer. Sempre bom ter alguém ponderado por perto pra segurar minha onda.
Código ingênuo
Quando estamos atacando um problema pela primeira vez é bem comum criar soluções muito muito ingênuas para esses problemas. Essas soluções até servem por um certo período de tempo mas logo se mostram insuficientes.
Olhando deste modo isso parece algo ruim mas é melhor optar por uma solução ingênua do que uma alternativa flexível que inevitavelmente traria complexidade desnecessária pra solução.
É importante entender que, com o tempo, vamos entendendo melhor o problema e adquirindo mais sabedoria sobre como resolver ele de uma maneira mais adequada. Esse é o momento de melhorar o código e jogar fora o código antigo (se não for possível melhorar ele).
Quando sabemos que esse momento chegou? Não sabemos. Provavelmente jogaremos fora esse código novo também. E assim a vida segue. Por isso chamamos de software ?
Um exemplo…
Já tive que implementar determinados tipos de código mais de uma vez ao longo da minha carreira. Alguns desses reincidentes são os sistemas de autenticação/autorização e os sistemas de assinatura/pagamentos.
É impressionante. Eu fiz errado na primeira vez, na segunda vez, na terceira vez, … e na última vez.
Em cada ocasião eu fiz o sistema mais flexível que o anterior e pensava: “dessa vez vai”. Não ia. Acho que nos cursos de Marketing e Administração eles ensinam uma matéria “Como encurralar Devs”. Eles sempre conseguem criar um modelo de assinatura, pagamento, pacotes de permissões, etc que você nunca imaginou. Sempre. Não tente lutar contra isso.
Por isso o melhor caso aqui é faça um código que só resolva o problema na mesa. Quando outro problema surgir, escreva um código que resolva os problemas que você precisa e jogue o anterior fora. Não tente prever os eventuais futuros problemas porque é perda de tempo.
Hoje eu terceirizo alguns desses sistemas sempre que dá. Desisti de tentar. Acho que é Senior que chama, né? ?
Remover código é bom
Como podem ver, tirando algumas exceções, apagar código é uma coisa boa. Vamos apagar código até termos “low code” ou “no code“… brincadeirinha ?
Quase todo desenvolvedor profissional vai ter que lidar com um banco de dados relacional ao longo de sua carreira. Os bancos de dados relacionais são uma daquelas ideias boas que a computação trouxe para o mundo.
Obviamente esses sistemas possuem limitações e essas limitações se dão tanto no nível conceitual como nas várias implementações de SGBD exitentes.
A limitação do modelo relacional existe porque não dá pra modelar o mundo que nos cerca usando conceitos tão “bidimensionais” como tabelas.
Ok, eu sei que dá pra modelar 3D, séries temporais, hierarquia, graphos, etc em bancos de dados relacionais, mas você vão concordar que as coisas começam a ter que ser ligeiramente “enjambradas” nas tabelas pra isso funcionar. E o funcionar ainda pode trazer algumas limitações.
Também tem as limitações de implementações do modelo. Os SGBDs ainda precisam saber se aquela coluna vai armazenar um texto ou um número e qual o tamanho esse dado vai ter.
Mas tem um negócio que é praticamente onipresente nos bancos de dados relacionais. O NULL.
O NULL serve para dizer que aquele dado, daquela coluna, naquela linha “não existe”. Não importa se essa célula de informação é um texto, uma data ou uma chave primária/estrangeira.
Ele também é um tipo de dado “complementar”, ou seja, você não diz que uma coluna da tabela é do tipo NULL. Você diz que aquela coluna é do tipo Xe também pode guardar um NULL. Ou seja, o valor NULL não é um tipo mas também serve a todos os tipos.
O NULL também é usado para modelar as relações entre os objetos de duas tabelas. É ele que vem como resposta ou influencia o resultado dos famigerados LEFT|RIGHT|INNER|OUTER|... JOINs que tanto demoram pra entrar na cabeça dos desenvolvedores.
O NULL é tão esquisito que força os programadores, tão acostumados com a lógica binária, a pensar em uma lógica com três estados.
Esses problemas mencionados até aqui podem ser extendidos aos nil, None de várias linguagens de programação, portanto, a dica que eu vou dar pode se aplicar em outros contextos: se você puder evitar usar NULL, faça isso.
Um exemplo do tipo de discussão sobre NULL causa aconteceu na nossa equipe. A gente está trabalhando em um sistema que cadastra perfis de cavalos. Então teremos nesse cadastro o nome do cavalo, a cor dele, a árvore genealógica, gênero, etc. Algumas dessas informações podem mudar ao longo do tempo (ex. um cavalo pode nascer de uma cor e mudar de cor na vida adulta). Outro problema que temos que lidar é com a fragmentação e qualidade dos dados das nossas fontes (ex. algumas base de dados que temos não informam a cor do animal).
Considerando esses requisitos e limitações é bastante comum que programadores, por reflexo, saiam colocando várias dessas colunas como NULLABLE no banco de dados. Mas isso trás alguns problemas que eu pretendo demonstrar (provavelmente de forma incompleta) abaixo.
Perda de Otimizações
Alguns SGBD podem perder otimizações em cenários onde temos colunas NULLABLE. Esse artigo aqui (inglês) tem uma explicação mais detalhada de um desses problemas.
O tipo de problema de otimização causado por colunas NULLABLE variam de SGBD pra SGBD, então recomendo que você faça uma busca por “nullable optimization [seu banco de dados]” no seu buscador favorito para entender o impacto do NULL no seu SGBD.
Pobreza Semântica
Quando usamos NULL no lugar de um valor real sabemos apenas que não temos aquele valor. Mas o que isso significa de fato? Não dá pra saber.
Vou dar um exemplo bem simplificado para ilustrar melhor… Imagine que temos um site de e-commerce e na nossa tabela de produtos (ex. Product) a gente tenha uma coluna para guardar o diâmetro do produto (ex. diameter). Na sua loja virtual você tem produtos com essa característica (ex. parafusos, canos, etc) e produtos que não tem essa característica (ex. caixa decorativa, piso porcelanato, furadeira).
A gente pensaria: esse campo é NULLABLE porque ele não precisa ser preenchido para todos os produtos.
Mas o que o não-valor NULL significa de verdade nesse contexto? significa que eu “não sei o valor” porque ainda não medi o objeto que está cadastrado no meu banco de dados? Significa que o valor diâmetro não se aplica àquele produto porque ele é uma caixa? Significa que ele ainda está aguardando a informação porque ela é preenchida de forma assíncrona por outro serviço ou equipe?
Não existe uma solução específica para adicionar mais semântica para esses dados. Existe um conjunto de técnicas e práticas que podem ser usadas pra resolver esse problema.
No caso da cor do cavalo que comentei acima, temos uma Foreign Key (FK) para uma tabela de cores oficiais de cavalo (sim, isso existe), o ideal seria criar uma cor NOT_AVAILABLE na tabela de cores e referenciar ela quando não conseguirmos determinar a cor do animal. Mas a mesma solução não serviria para a data de nascimento dele.
Como temos diferentes tipos de informação que podem ou não estar disponíveis precisamos criar uma modelagem específica para lidar com isso.
Coalescing
Quando dizemos que uma coluna é de um tipo específico podemos fazer nossas queries e nosso código sempre assumindo que o dado retornado é daquele tipo.
Saber disso diminui a complexidade do nosso código porque não precisamos ficar lidando com um cenário excepcional onde o tipo do dado muda nem ficar convertendo esse dado de um formato para outro.
NULL é inevitável
Infelizmente nem sempre é possível evitar o uso de NULL. Eventualmente precisamos recorrer à ele ou preferir ele à outras opções.
Se eu tenho uma coluna birthdate e nem sempre eu terei essa informação para preencher no meu banco de dados é preferível usar NULL do que armazenar uma data inválida tipo 00/00/0000. Usar uma data inválida só vai servir pra mudar a complexidade de lugar (quando precisar calcular a idade da pessoa preciso excluir datas zeradas pra não ter alguém com 2020 anos).
No caso do diâmetro que eu mencionei acima, podemos usar um 0 pra sinalizar que o objeto não tem diâmetro. Mas fazer isso pode trazer problemas e complexidades para o sistema de shipping fazer o cálculo da volumetria do objeto pra calcular o frete. Nesse caso usar NULL pode fazer mais sentido (e usar uma segunda coluna pra adicionar semântica à esse NULL).
Conclusão
NULL não é inerentemente ruim e não estou desaconselhando ele. O objetivo desse artigo é só “desligar o automático” na cabeça dos desenvolvedores na hora de tornar uma coluna NULLABLE.
E quando estiver usando NULL é importante redobrar a atenção com seu código e com seus dados.
PS. NULL significa Zero em Alemão. Então eu abro exceção e tomo Coca-Cola Null Zucker (zero açucar) por aqui. 😉
Depois de algum tempo escrevendo código com testes automatizados eu comecei a considerar que cursos e livros sobre esse assunto fossem sempre um tipo de “falcatrua”. Achava que ensinar a fazer testes não fazia muito sentido.
Mas quando abri minha empresa de consultoria e treinamento eu recebia vários pedidos de clientes para ministrar um “Curso de TDD” para suas equipes. Então resolvi desenvolver esse curso.
Só uma observação: eu uso teste automatizado e não ao longo desse texto porque é importante saber que TDD é uma técnica de desenho e modelagem de código que usa testes automatizados mas tem muito software com testes automatizados que não foram criados com TDD.
Voltando para o curso…
O curso ficou bem legal e os slides estão disponíveis gratuitamente hoje em dia, já que não vendo mais ele e nem tenho mais a minha empresa.
Ter desenvolvido esse curso mudou a minha visão sobre ensinar testes com cursos e livros? Não mudou.
Prática vs. Perfeição
Eu continuo achando que só é possível aprender a escrever testes na prática. E durante o curso, como vocês podem ver nesse slide, eu menciono isso para não alimentar falsas expectativas de que cada aluno ali seria um “mestre dos testes” após concluir o meu treinamento.
Eu estabeleci um paralelo entre aprender escrever testes com aprender uma arte marcial. E usei a figura do Sr. Miyagi ensinando caratê pro Daniel San (ok, eu sei que sou velho mas me recuso a usar a figura do tira-casaco/coloca-casaco que ensinava Kung-Fu).
E, tal como nas artes marciais, você não aprende a escrever testes em livros e cursos.
Resolvi estabelecer uma proposta “ousada” para o curso: não ensinar a escrever testes.
No lugar disso o curso daria uma fundamentação sobre o que é teste, pra que servem, a importância deles, e desmistificaria algumas bobagens que dizem sobre eles (ex. cobertura de 100% é essencial, código com testes não tem bugs, etc). Depois a gente teria algumas atividades práticas controladas (as tão temidas “dinâmicas”).
Em uma dessas dinâmicas eu criava uma atividade parecida com a de um Coding Dojo com os alunos. O problema em todas as turmas era sempre o mesmo: converter números para algarismos romanos.
Essa dinâmica baseada em Coding Dojo servia muito bem no processo seletivo de uma outra empresa onde trabalhei mas isso é assunto para outro artigo.
Eu observava a dinâmica mas não trabalhava no problema. Eu tomava nota de algumas coisas da atividade e, no final, a gente discutia o que havia acontecido de errado, o que tinha dado certo e eu ia encaixando os tópicos de TDD para serem ilustrados pelo que eles experimentaram.
Depois disso a gente passava por mais alguns fundamentos e retornávamos para a prática.
A segunda atividade era escrever um encurtador de URLs completo na linguagem/framework que a empresa usava ou com o qual a maior parte da equipe estava mais familiarizada.
Nesse momento a gente aprendia como organizar melhor os testes, como usar as ferramentas de teste e até como fazer TDD. Essa atividades levava de 1 a 2 dias e eram feitas em duplas (pair programming) que eram trocadas a cada 2 horas (o critério de troca era misturar abordagens das diferentes duplas com programadores(as) diferentes).
Por fim eu indicava alguma literatura complementar (majoritariamente como referência) porque obviamente eles aumentam a sua compreensão sobre testes automatizados mesmo não sendo a fonte principal de aprendizado.
Uma curiosidade sobre a dinâmica do Coding Dojo com o problema dos algarísmos romanos: eu ministrei esse treinamento para 5 turmas diferentes. Das cinco turmas que trabalharam no problema, cada uma delas entregou solução completamente diferente umas das outras. Todas funcionavam e atenderiam tranquilamente requisitos de performance, uso de memória, etc. Engraçado notar como pessoas e times possuem perspectivas tão distintas sobre os problemas apresentados.
Não é fácil mas é possível
Infelizmente é impossível aprender a escrever testes sem praticar. Mas eu garanto que vale a pena tentar.
Vai ser frustrante e lento no início mas depois as coisas aceleram.
E entenda que o seu “caratê” vai ser bem ruim no começo e, talvez, no futuro, ele fique ótimo. Você pode até chegar à faixa preta mas atingir a perfeição é impossível.
Por conta dos seus testes serem ruins no começo eles vão gerar um grande esforço de manutenção. Aquele refactoring ou bugfix “trivial” vai te garantir horas de reescrita de testes. Desistir vai parecer uma ótima ideia nessas horas. E é aí que você vai precisar perseverar. Entenda que isso acontece porque seus testes ainda não estão muito bons (ou ainda que o seu código sendo testado precise de algumas melhorias).
E quando você não conseguir mais programar sem testes você vai ver que valeu a pena.
Os amigos que me conhecem sabem que adoro livros. Para o desespero da minha mulher e das finanças da casa tenho o mal hábito de comprar muito mais livros do que consigo ler.
Recentemente isso ficou pior porque comprei um leitor eletrônico que permite comprar coisas com um toque na tela. Pelo menos o problema com o espaço para os livros foi resolvido.
Programo computadores desde muito cedo mas nunca tive muito estudo formal sobre o assunto (não sou graduado) então sempre dependi dos amigos mais inteligentes e dos livros para aprender as coisas. Alguns foram bem importantes pra mim e esses eu vou listar aqui.
Os meus caminhos de aprendizado sempre foram tortuosos e fragmentados então a lista não tem nenhuma sequência que precise ser seguida. Estão na ordem como fui lembrando deles.
Os livros com links são os que ainda podem ser adquiridos pela internet e que eu ainda recomendo a aquisição por não estarem defasados.
Se você tem sugestões de livros que foram importantes para você, escreva nos comentários.
Revistas de Eletrônica
Ok, não são livros mas foram importantes para mim. Antes de programar eu brincava de montar circuitos eletrônicos. Como eu era muito novo (uns 9 anos) não me lembro de muitos detalhes de todas as revistas mas algumas foram especiais:
Experiências e Brincadeiras com Eletrônica Júnior – gostava tanto dela que ganhei uma assinatura do meu pai. Era publicada pela editora Saber e tinha projetos mais simples e menos “sérios”. Adequado para crianças.
Be-a-Bá da Eletrônica – Era formatada como mini-cursos e cada edição abordava um tópico específico. Trazia uma placa de circuito impresso para fazer a montagem do circuito principal.
Infelizmente nenhuma das duas é publicada mais. Acho que a revista que chega mais próximo delas é a Eletrônica Total da Editora Saber.
Aprendizado Inicial
Quando eu comecei a aprender a programar as únicas fontes de informação que eu tinha eram os 2 livros que acompanhavam meu computador e a revista Micro Sistemas. Numa segunda fase, também de aprendizado inicial, passei a estudar mais a fundo o universo dos IBM PCs e do MS-DOS.
Livros
Basic MSX – da editora Aleph e editado pelo famoso Prof. Pier (Pierluigi Piazzi). Era uma referência com os comandos e funções da linguagem Basic que acompanhava meu computador.
Dominando o Expert – também da editora Aleph e editado pelo Prof. Pier. Era um curso introdutório de informática usando Basic. Foi com esse livro que digitei meus primeiros comandos num computador.
Clipper Summer’87 Cartão de Referência (Rubens Prates) – não é bem um livro mas aprendi o básico de Clipper.
Clipper Summer’87 vol. 1 e 2 (Antonio Geraldo da Rocha Vidal) – com esses livros aprendi a desenvolver aplicativos comerciais e, a partir desse ponto, passei a trabalhar com programação. Tinha 12 anos.
Algoritmos e Estrutura de Dados (Niklaus Wirth) – apesar do livro não usar Pascal nos exemplos de código eu conseguia facilmente adaptar o código para Pascal (do Turbo Pascal 4 até o Turbo Pascal 7). Foi quando aprendi a programar em Pascal. Na minha opinião, hoje, existem livros melhores sobre estruturas de dados e algorítmos.
C Completo e Total (Herbert Schildt) – eu aprendi a programar em C “sozinho” mas sonhava em comprar esse livro. Como não tinha dinheiro eu lembro de ir até a livraria para ler ele. Só depois de velho consegui verba pra comprar uma cópia dele pra mim.
MS-DOS Avançado (Ray Duncan) – livro que ensinava desenvolvimento de software para DOS em Assembly e C.
Como vocês notaram o meu aprendizado era focado mais em novas linguagens de programação e em programação “baixo nível” (única exceção foi o Clipper que usava para “pagar as contas”).
Revistas
Micro Sistemas – “A primeira revista brasileira de microcomputadores” era o subtítulo dessa revista. Ela vinha com reportagens e listagens de programas enviados pelos leitores (publicaram um artigo meu).
CPU MSX – Comprava algumas edições dessa revista também. Também tinha artigos interessantes sobre jogos e programação mais avançada (muito tempo digitando as listagens com códigos hexadecimais dos programas em linguagem de máquina).
INPUT – Coloquei em Revistas porque ela vinha em fascículos mas, depois de encadernadas, produziam 5 volumes enciclopédicos. Essa coleção, até hoje, é uma referência para questões didáticas. Sempre que preciso explicar alguma coisa para alguém recorro à essa coleção para ver qual a abordagem que eles usaram.
Microcomputador Curso Básico – 2 volumes da editora Globo (ou Rio Gráfica). Folheava tanto esses livros que eles acabaram gastos. Gostava da seção Raio X onde eles tiravam fotos de vários computadores abertos e apresentavam a ficha técnica deles. Ficava imaginando o dia que poderia ganhar alguns deles 🙂
Fase Unix/Linux
Eu me divertia horrores programando para essas máquinas com “tela preta”. Vocês não imaginam a minha tristeza quando todo mundo começou a usar interfaces gráficas (Windows).
A coisa legal é que, bem nessa época, eu fui até uma feira em São Paulo (Fenasoft) onde vi um troço chamado Unix. Era uma estação da Silicon Graphics no estande da Globo. Ela tinha interface gráfica mas você ainda tinha que digitar comandos num terminal texto para operá-la. Provavelmente era um Irix.
Como eu tinha um PC/Intel em casa, eu não conseguiria rodar esses Unixes que vi na feira e comprar uma máquina daquelas… fora de cogitação. Fiquei com aquilo martelando na minha cabeça até começar o meu estágio e operar um 386 com SCO Unix (e outro com Xenix).
Vi que existiam Unixes para PC/Intel, mas todos eram caríssimos (não rolava piratear porque não davam acesso aos disquetes originais para um reles estagiário).
Quando reclamei sobre isso com um amigo que estudava computação no Ibilce ele mencionou um tal de Linux. Pedi para um “cara” na cidade que tinha internet rápida e um gravador de CDs gravar um CD com Linux pra mim e assim ele o fez. Era um Slackware.
Decidi aprender a usar aquilo e, para isso, precisava instalar mais um SO no meu computador que já tinha MS-DOS, Novell DOS 7, OS/2 (usado na minha BBS) e Windows 95/98.
Me dediquei com afinco (precisou porque apanhei muito) até aprender bem a usar aquilo.
Mas a coisa ficou séria mesmo quando, por uma dessas pegadinhas do destino, eu comecei a trabalhar na equipe de desenvolvimento do Conectiva Linux em Curitiba.
Quem me ajudou mesmo foram os colegas de trabalho… Mas alguns livros que li na Conectiva e, posteriormente, nos diversos outros lugares em que trabalhei ajudaram muito também.
Livros
Aprenda em 24 Horas Unix (Dave Taylor) – sério. Muita gente tem preconceito contra esse tipo de livro, mas para um cara que já conhece várias coisas e precisa aprender a “se virar” com uma tecnologia nova eles são ótimos. É um livro para iniciar e te dar referências para aprofundar os estudos.
Maximum RPM (Edward C Bailey) – não é um livro sobre programação (fala sobre fazer pacotes RPM para RedHat) mas foi um divisor de águas. Nem é um livro bom, mas aprendi a fazer build de vários softwares (e entender o ./configure; make; make install). Além disso, ele é em inglês e, digamos, eu não lia nada em inglês na época. Precisava aprender a fazer pacotes RPM se quisesse garantir meu emprego na Conectiva. E garanti.
Expressões RegularesUma abordagem divertida (Aurélio Jargas) – o Aurélio era meu colega de trabalho e aprendi Expressões Regulares com ele pessoalmente e não com o livro. Mas tudo que ele me ensinou está no livro também, logo, vou colocar ele nessa listagem. É impressionante a didática dele para ensinar um assunto tão complicado.
Shell Script Profissional (Aurélio Jargas) – o mesmo caso aqui. Eu não li o livro, mas boa parte do que sei sobre programação shell eu aprendi com o Aurélio. O conteúdo que ele me passou está todo aí.
Instant Python (Magnus Lie Hetland) – ok, é só um artigo sobre Python e não um livro. Mas esse artigo (traduzido pelo meu chefe) me apresentou a linguagem Python e, desde então, essa tem sido a minha principal ferramenta de trabalho. Mesmo tendo aprendido novas linguagens e trabalhado com outras sempre volto a trabalhar com Python. Dá para acreditar que aprendi Python com esse artigo?
Fase OOP – Object Oriented Programming
Depois que saí da Conectiva tive um breve período como sysadmin em uma empresa e desenvolvia mais scripts do que aplicações “de verdade”.
Mas depois desse emprego circulei por diversos outros onde, de fato, voltei a programar computadores mais seriamente.
Como a maioria desses trabalhos usavam linguagens com paradigma orientado a objetos acabei focando em livros que tratem esse tipo de assunto.
Fundamentos do Desenho Orientado a Objetos com UML (Fundamentals of Object-Oriented Design in UML) de Meilir Page-Jones – esse livro foi responsável pela minha “iluminação” com relação ao desenho orientado a objetos. Até então eu só tinha feito código procedural (mesmo em Python!) porque não entendia muito sobre o OOP. O livro usa UML para ilustrar os assuntos mas ele usa UML como deve ser usada: apenas para ilustrar algum conceito. Nada do pedantismo da UML e seus vários tipos de gráficos. Infelizmente a versão traduzida desse livro saiu de circulação, mas ainda é possível encontrar o original em inglês.
Padrões de Projeto ou Design Patterns (GoF) – a primeira parte desse livro é importante e tem várias ideias importantes para qualquer programador que queira usar OOP. A segunda parte é mais para referência, mas tem alguns patterns bacanas.
eXtreme Programming Explained (Kent Beck) – livro que me apresentou o conceito de programação “ágil”, testes automatizados, refatoração, etc. Não tem código mas os conceitos são extremamente poderosos. E o Kent Beck é um excelente autor. Tem uma capacidade invejável de explicar qualquer coisa de forma simples. Esse livro teve uma tradução muito boa mas parece ter saído de circulação.
Refatoração ou Refactoring (Martin Fowler) – livro elabora melhor a idéia de refatoração citada no livro de XP do Kent Beck. O capítulo sobre “Bad Smells” (Mal cheiros) foi escrito pelo Kent Beck e é uma das melhores partes do livro. Atualização: saiu uma segunda edição desse livro e uma boa tradução dessa segunda edição. Os exemplos do livro, que eram em Java, agora estão em Javascript.
Pragmatic Programmer (David Thomas & Andrew Hunt) – ganhei esse livro de um amigo e, para mim, ele é fundamental. Todo programador deveria ler. Fala sobre um monte de coisas. De ética à teste automatizado. De técnicas de depuração às linguagens de programação.
Code Complete 2nd ed. (Steve McConnell) – esse livro fala sobre assuntos muito similares aos que você encontrará no Pragmatic Programmer. A diferença é que neste livro ele usa uma abordagem menos “pragmática/ágil” e se aprofunda mais nos assuntos. É um livro bem mais denso. Li a versão original, mas já existe tradução.
Test-Driven Development by Example (Kent Beck) – eu já tinha lido sobre TDD no livro de XP do Kent Beck mas não tinha a menor idéia do que ele estava falando. Já nesse livro aqui eu consegui compreender a mecânica da coisa. O Kent Beck tem o dom de escrever as coisas de forma simples e objetiva. Vale a pena. (Atualização: remoção da referência sobre a tradução pois aparentemente ela parou de ser editada)
(Atualização) Growing Object-Oriented Software, Guided by Tests (Steve Freeman) – o livro do TDD by Example do Kent Beck é a melhor introdução ao tópico, mas ele vai até o ponto onde ele te ensina a testar. Esse livro aqui te pega nesse ponto e leva adiante para te ajudar a testar software real.
Clean Code (Uncle Bob) – apesar do autor ser um ser humano desprezível o conteúdo técnico desse livro é bom e escrito de forma simples e fácil de ser compreendida. Nesse livro o Uncle Bob fala sobre como escrever código limpo e bem arquitetado. Existe uma tradução desse livro mas eu provavelmente não recomendaria porque a editora que publica a tradução tem uma péssima reputação nas suas traduções. (Atualização: Adição desse livro)
Advanced Programming in the UNIX Environment (Richard Stevens) – esse livro não era meu e nem cheguei a ler ele inteiro. Para ser honesto eu li uns 2 ou 3 capítulos apenas. Mesmo assim tudo o que eu sei sobre sockets e sobre chamadas como fork/exec do Unix eu aprendi nesse livro. Esse tipo de conhecimento é superimportante para programadores e existem diversos livros que tratam dele. Esse do Stevens é o que mais me ajudou. (Atualização: eu recomendaria provavelmente o livro The Linux Programming Interface atualmente. É um livro ótimo, mais moderno e atual e não perde muito tempo com alguns assuntos que já caíram em desuso)
Introduction to Algorithms (Cormen, Leiserson, Rivest, Stein) – obviamente não li esse livro inteiro. Mas foi o livro que me ensinou o significado da notação big-O para eficiência de algoritmos. Ele ensina a calcular, mas confesso que foi além da minha capacidade intelectual. O restante do livro pode ser lido, mas me parece mais adequado para consulta e referência. Ele lista diversos tipos de algoritmos. Existe tradução.
Conclusão
Depois desses livros eu comecei a me interessar por outros assuntos voltados ao empreendedorismo que também foram muito importantes. Mas vou deixar isso para outro artigo.
Já é de conhecimento de todos que trabalho com computação já faz muito tempo. Vi muitas ondas passarem.
Quando comecei com BASIC em máquinas de 8bits vi a primeira onda chegar… eram as linguagens estruturadas. Linguagens “procedurais”… código sem GOTO, etc. Quem programava só em BASIC e não conhecia esse “novo paradigma” (aspas propositais) estava fadado ao fracasso e ao ostracismo. Não mereceriam ser chamados de programadores.
Parti para a luta e fui aprender Pascal, C e/ou Clipper.
Ondas tecnológicas
Assim que dominei esse “novo paradigma” avistei outra “nova onda”: Programação Orientada a Objetos.
Essa foi uma das primeiras grandes ondas que contaram com apoio de Marketing de grandes empresas. Lembro-me de ler sobre “orientação a objetos” até em jornais de bairro (hipérbole detectada!). E mais uma vez fui convencido de que se não dominasse esse “novo paradigma” eu estaria fadado ao esquecimento.
Então comecei a estudar o assunto e no meu entendimento inicial (e duradouro) uma “classe” nada mais era do que um “struct” (ou RECORD) com esteróides. Ainda existem registros da minha primeira incursão nesse novo mundo. Eu só fui entender melhor OOP recentemente.
Outra onda que “bombou” mais ou menos na mesma época era a dos bancos de dados relacionais (SQL e afins). Mas eu não tinha muito contato com esse mundo que era restrito às “elite$”.
E com OOP e SQL essas empresas de marketing que, eventualmente, produziam software começaram a ganhar rios de dinheiro vendendo “gelo para esquimó”.
A tecnologia dos computadores surgiu para empresários em mensagens como: “Se sua empresa não usar OOP ou SQL você (perderá dinheiro|será devorado pela concorrência|será feio e bobo).” — (IBM|Gartner|Oracle)
Os empresários eram completamente ignorantes sobre esses assuntos e, num ato de fé, acreditavam em tudo o que as “IBMs” diziam. Afinal elas ficaram grandes e ricas por lidar com tecnologia, certo? Conseguem detectar a falha primordial nesse raciocínio?
Esse tipo de mensagem juntamente com a outra que dizia: “ninguém é demitido por ter escolhido IBM” fez muito bem para o lucro dessas empresas.
Naquela época isso fazia sentido, afinal, os computadores não faziam parte da vida de todo mundo. Tecnologia e mágica eram sinônimos. Mas hoje isso não deveria mais ser assim. A fábrica de “hypes” continua funcionando e os empresários e profissionais da área continuam investindo em tecnologias “da moda” apenas por estarem na moda.
Outras “ondas” movimentaram e ainda movimentam o mercado e com certeza não lembrei de todas: OpenSource, Java (J2EE), XML, NoSQL, Cloud, metodologias de desenvolvimento (ágeis ou não), Big Data, Internet of Things, Frontend/Backend engineering, etc.
Para cada uma delas temos defensores (não é uma onda! é realidade! olha só isso aqui!) e detratores (isso é hype! isso não funciona!). Ambos estão certos e errados.
Meus amigos devem estar pensando: “Mas ele é o cara que mais compra esses hypes! Andava com uma camiseta ‘você ainda usa banco de dados?’!”.
Eu, de fato, acompanho todas essas ondas. Cada uma delas acrescenta algo na minha caixa de ferramentas. Sempre que vejo uma delas chegando já vou logo dando uma chance pra elas se provarem úteis. Mas isso não significa que vou adotá-las em tudo o que farei e que as coisas antigas são lixo.
É o velho clichê: existem ferramentas certas para resolver cada tipo de problema.
Resolvi escrever isso pra que vocês possam refletir sobre a adoção racional de tecnologias. Usar critérios técnicos para a escolha e não ficar pegando jacaré em qualquer onda que aparece.
Outra coisa importante é não parecer bobo falando que você faz “Big Data” pra um cara que já processava toneladas de dados antes mesmo de terem cunhado essa expressão. Ou falar que usa NoSQL pra um cara que já usava Caché (kind of OODBMS), LDAP (hierárquico), ou Isis (schemaless).
Como vivi todas essas ondas eu saco logo que esses caras são mais “gogó” do que outra coisa.
Mantenham o foco em criar coisas boas que resolvam problemas importantes e escolham tecnologia usando critérios técnicos.
Ser proficiente numa linguagem é um critério muito importante mas ele deve ser considerado em conjunto com outros critérios (robustes, disponibilidade de recursos, etc).
Dia desses vi um anúncio procurando programador Clipper e pensei: esse contratante deve ter um excelente software. Deve ser um software tão bom e deve resolver problemas tão importantes que ele resistiu à várias ondas e não virou areia.